Configuration
You can use Spectral without any configuration. You may want to configure Spectral in the following cases:
- Special treatment of source root: in a given repo or folder, include specific folders, exclude others
- Scan-time ignores: ignore classes of files or detectors, or pieces of text at scan time (you can also perform ignores in your Spectral account)
- Detector inclusion or exclusion: for cases where you want to disable existing detectors, or enable experimental ones
- Output formats: you can switch output formats to JSON, JUnit, and others, which can help shape your pipeline automation
- Custom detectors: Spectral can load custom detectors that you build, and you can specify where it is in the configuration
We assume you have a copy of Spectral, if not -- check out the getting started section. Then use
spectral initto generate a base configuration.
$ $HOME/.spectral/spectral init
Initialized your spectral configuration in '.spectral/'.You should now have a starter configuration layout in a special .spectral folder like so:
$ tree .spectral
.spectral
├── rules
│ ├── merchants.speql.yaml
│ └── sample.yaml
└── spectral.yaml
1 directory, 3 filesYou should check this folder into source control.
Spectral.yaml
This is the main Spectral configuration file. It configures Spectral for:
- Input sources -- what paths to scan
- Ignores -- what to ignore and at what stage to apply ignores
- Reporter outputs -- what reporter module to activate
- Detectors -- what detectors to include and/or exclude
- Metadata -- what kind of extra functionality to activate such as masking, debug run and so on
# you can omit the reporter section entirely (you'll get a stylish reporter by default)
reporter:
outputs:
stylish: {} # nice looking CLI reports
# stylish: { html: "output.html" } # produce HTML reports
# stylish: { csv: "output.csv" } # produce CSV reports
# log: # use a logger
# json: true # enable JSON logging
# file: out.json # put output in a file
# junit: {} # Great for integrating with CI systems that understand JUnit XML (all of them, probably)
# ignores: {} # A reporter output that streams results as ignores
#
# Ignoring Matches
#
# you can specify ignores for matches that you know exist
# and acknowledge them, but you don't care about them for now.
#
# These are regex: rule_id, rule_name, match_text, path.
# To get a fingerprint, run `spectral fingerprint --text YOUR-SECRET`
#
# match_ignores:
# ignores:
# - match_text: MYSQL_ROOT_PASSWORD
# - rule_id: <rule id>
# rule_name: <rule name>
# match_text: <rule id>
# path: <path>
# match_fingerprint: 79cdb7f2e0e4a96520304ff641f45f230be4f362a4a16c704730115a85fa545f
projects:
sample:
project:
name: sample
input:
- local: .
name: sources
# you can add a few more.
# everything is relative to working directory (where you run spectral from)
#
# - local: nteract/node_modules
# name: nteract
rules:
roots:
- rules # folder(s) relative to this file
# cherry-pick rules for these roots
# include:
# tags:
# - node
# ids: []
# exclude:
# tags:
# - node
# ids: []
# add as many more projects as you like:
# all_pythons:
# ...🦸♀️ Want to exclude rules by severity? You can use the include/exclude tags section for that, so for instance, if you want to see just errors, you can use the tag error in the include, or use the exclude tags warning and info which will gives the same semantic.
You can use the include/exclude tags also via CLI options, e.g:
--include-tags erroror--exclude-tags warning,info.
Ignores
You can run a scan, and choose to ignore results, possibly because they're known issues, or should be addressed later, in either way -- you want to take control of your risk yourself and explicitly ignore findings.
There are 3 main ways to perform ignores:
- Glob ignores - don't process the files, skip completely
- Match ignores - ignore actual matches by file name, content, rule, and more from .spectral/spectral.yaml
- Inline Code Ignores - ignore actual matches from inline source code
🦸♀️ Why more than one way to ignore? Match ignores will work most of the time. If you don't want to scan a large model file because it's a waste, you can use a glob ignore to skip it completely.
Glob Ignores
You might want the same experience as working with a .gitignore file, ignoring an entire folder, a glob of a file structure or a specific file, regardless of any scan.
A good example might be a Tensorflow model, which weighs gigabytes, and you have reasonable certainty there couldn't be any security issues there (a fairly reasonable assumption).
To ignore using this technique, add a special .ignore file to your repo, and set its content much like a regular .gitignore
tf-models/*When using Spectral Scan, these files will not be considered at all, when Spectral is compiling its execution plan.
🦸♀️ Spectral respect .gitignore like the .ignore Spectral respect the .gitignore file the same as .ignore, so in case there is .gitignore in the root of the scan, all the glob's inside the .gitignore file will be ignored and will not be processed.
Match Ignores
You have the option of ignoring matches. This ignore feature is the most powerful, and you're able to specify actual finding text to ignore such as test keys, demo keys, and more.
Ignoring matches after they were found, is called "match_ignores" in Spectral. Example: .spectral/spectral.yaml
There might be a case where you want to ignore a specific rule, and under that rule, ignore a specific set of files.
For example, you want to ignore all credit cards showing under a "test" folder. In that case, you want to specify the PCI rule and under it specify a file glob such as tests/.*. In this case we use a regular expression which is a bit more costly than a glob but much more powerful and expressive.
Adding ignores is done by editing your main spectral configuration file (spectral.yaml), like below:
match_ignores:
ignores:
- match_text: MYSQL_ROOT_PASSWORD
- rule_id: <rule id, regex>
rule_name: <rule name, regex>
match_text: <rule id, regex>
path: <path, regex>
match_fingerprint: b76fe610abe3bdaa92d4002dc0516dfa21c2dbf520373c6203469d0dee369888Fingerprinting
When you want to ignore a secret, or a piece of confidential text, it doesn't make sense to specify it verbatim as an ignore because you'd be duplicating the secret. For this case, we use a cryptographically secure digest fingerprinting. To fingerprint your piece of text, you can use Spectral itself:
$ spectral fingerprint --text AKIAXXXXXXXXXXXXXXXX
b76fe610abe3bdaa92d4002dc0516dfa21c2dbf520373c6203469d0dee369888Then, you can safely add this fingerprint to your ignore rule, which will ignore the content behind the fingerprint.
Inline Code Ignores (supported in version 1.10.100)
To provide more flexibility, we support adding ignores in your source code (as code comments) using the following pattern:
spectral:ignore-[file|next-line|line] [detector|fingerprint|text] [COMMENT]Modes
spectral:ignore-line - Ignore match in the same line
spectral:ignore-next-line - Ignore next line match
spectral:ignore-file - Ignore in all file
Categories (supporting multiple values, comma separated)
detector - Ignore by specific detector id.
fingerprint - Ignore by specific fingerprint.
text - Ignore text prefix
Examples
-
Ignore match in the same line by detector
AKIAXXXXXXXXXXXXXXXX // spectral:ignore-line detector:CLD001 -
Ignore match by a fingerprint
For getting the fingerprint run the following command:$ $HOME/.spectral/spectral fingerprint --text AKIAXXXXXXXXXXXXXXXXAKIAXXXXXXXXXXXXXXXX // spectral:ignore-line fingerprint:b76fe610abe3bdaa92d4002dc0516dfa21c2dbf520373c6203469d0dee369888 -
Ignore match by text prefix
AKIAXXXXXXXXXXXXXXXX // spectral:ignore-line text:AKI -
Ignore multiple categories
AKIAXXXXXXXXXXXXXXXX // spectral:ignore-line detector:CLD001 text:AKI -
Describe the ignore by a comment field
AKIAXXXXXXXXXXXXXXXX // spectral:ignore-line detector:CLD001 comment:'Testing token' -
Ignore multiple detectors in file
// spectral:ignore-file detector:CLD001,CLD002
Ignore Rules Categorization (supported in version 1.10.189)
Categorization is designed to enhance policy compliance within organizations by providing visibility into all ignores, whether defined in the Spectral configuration YAML file or inline in the code. This feature allows categorization of ignores to ensure they are tracked appropriately, aligning with the organization's policy compliance efforts.
YAML Configuration
In the Spectral configuration YAML file, match ignores can be categorized as follows:
match_ignores:
ignores:
- rule_id: CLD001
categorization:
kind: wont-fix | false-positive
comment: "Test secret"Inline Configuration
For inline ignores, the categorization is added as follows:
// spectral:<ignore-kind> detector:<detector> categorization:<false-positive | wont-fix> comment:<comment>
example
// spectral:ignore-next-line detector:CLD001 categorization:false-positive comment:'Test secret'When Spectral detects an ignore with categorization, this issue will be send to SpectralOps dashboard.
Users will not be able to change the ignore category or comment, nor resolve the issue from the dashboard. Management of these ignores is handled exclusively by the scanner.
Hardening - Hide Local Ignores
The hardening feature allows organizations to enforce stricter controls on local ignores.
For example, if an organization wants to track all issues ignored by users, they can use the hardening feature to restrict local ignores, ensuring that all ignores are categorized and visible in the dashboard.
When restricted, all local ignores must have a categorization.
Ignores without categorization will fail the scan or will be dropped, according to the fallback mode.
Projects
When you have a top level folder, that is divided to sub-folders you wish to scan separately since each of them is representing an asset, this configuration would be useful for you.
An example for common usage for this configuration is a monorepo.
Lets say we have a monorepo, which have sub folders such as client, backend, and infra (Infrastructure as code).
The configuration for this project would look like:
projects:
infra:
project:
name: infra # Name of the project
input:
- local: ./infra # Path of sources to include in project
name: sources # Name of the path
rules:
roots: # Rules paths on client machine - you can add paths to custom rules you created (relative to `spectral.yaml` location - `.spectral/spectral.yaml`)
- rules # This is the default if not set (`.spectral/rules`)
include:
ids: [] # Ids of rules you wish to include in this project
tags: # Tags you wish to include in this project
- iac
exclude:
ids: [] # Ids of rules you wish to exclude from this project
tags: # Tags you wish to exclude from this project
- audit
client:
project:
name: client
input:
- local: ./client
name: sources
rules:
include:
ids: []
tags:
- audit
- base
exclude:
ids: []
tags:
- iac
server:
project:
name: server
input:
- local: ./server
name: sources
rules:
include:
ids: []
tags:
- audit
- base
exclude:
ids: []
tags:
- iacGiven this configuration, spectral scan command would trigger 3 scans (one scan per project defined in the configuration).
Properties
project- Mandatoryname- Mandatory
input(Array) - Path of sources to include in project - Mandatory, each element should consist of:local- Path of resources to include in this project - Mandatoryname- Name for given path - Mandatory
rules- Configuration regarding rules to scan in this projectroots(Array) - Rules paths on client machine - you can add paths to custom rules you created (relative tospectral.yamllocation -.spectral/spectral.yaml) - Not mandatoryinclude- Configuration about excluding rules in this projects - Mandatory ifexcludewas not providedtags(Array) - Collection of tags to include in this project (iac,auditetc.) - Mandatoryids(Array) - Collection of rule ids to include in this project (DB001, TFAWS110 etc.) - Mandatory
exclude- Configuration about excluding rules in this projects - Mandatory ifincludewas not providedtags(Array) - Collection of tags to exclude in this project (iac,auditetc.) - Mandatoryids(Array) - Collection of rule ids to exclude in this project (DB001, TFAWS110 etc.) - Mandatory
Configuration per asset type
With spectral.yaml you can set configuration for a specific asset, and only for file based assets.
Besides spectral.yaml, Spectral enables to set configuration that would be applied on all assets of the same type, and this is available for all types of assets (git, host, log, jira etc.).
Setting this configuration can be done in your account at Spectralops.io, by going into the Settings screen, and then get into Scan configuration page.
In this page, choose the type of asset to apply the configuration on, and set the configuration in the input as YAML (in the same format & structure as in spectral.yaml).
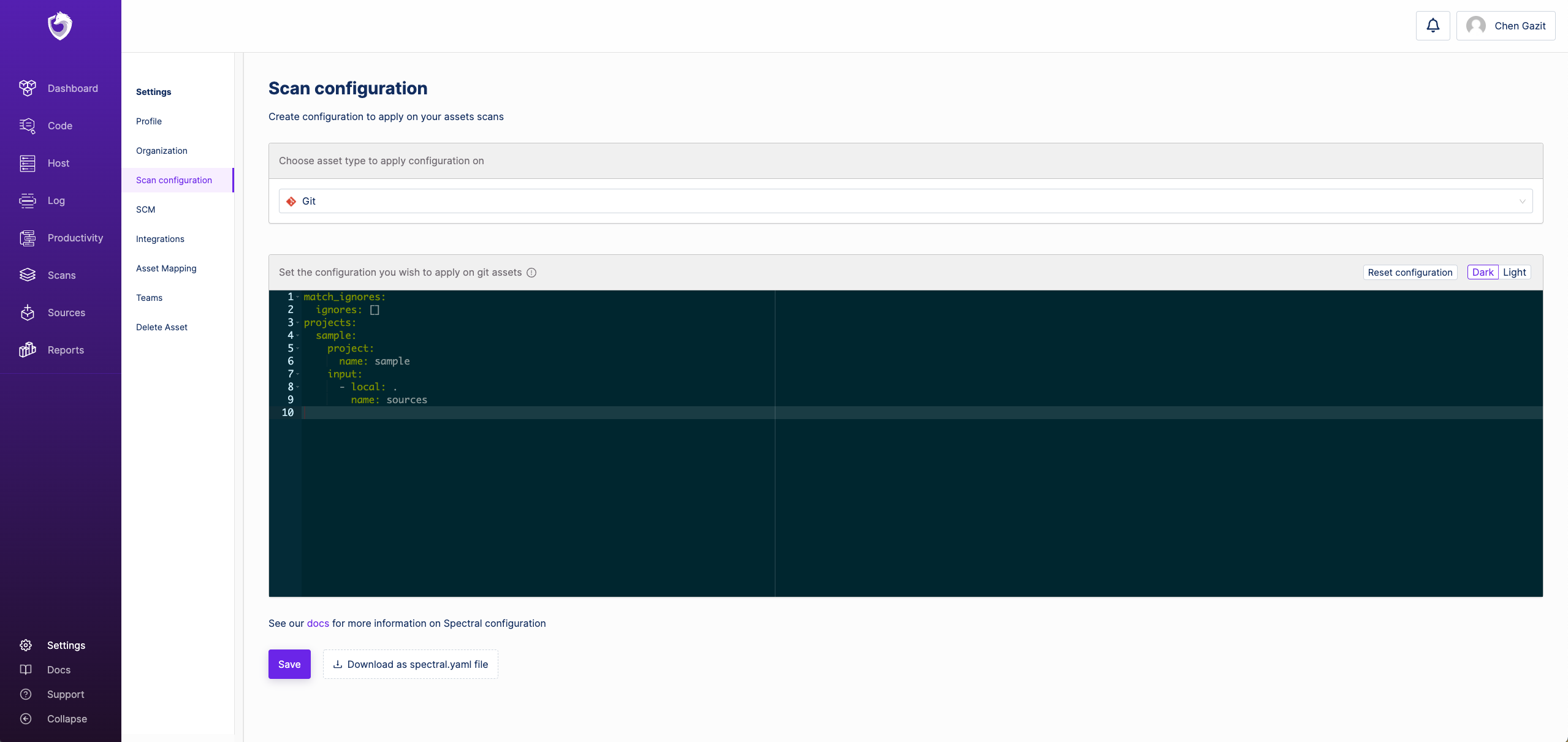
You can disable this configuration from taking place in an asset scan by adding the
--ignore-remote-configflag while executing your scan, for example:spectral scan --ignore-remote-config
Fallback mode
Spectral provides users with various flags and settings to customize the scanning process. By default, the tool enforces strict validation of user configurations. However, we have introduced a fallback mode that offers greater flexibility in handling misconfigurations.
Configuration Modes
By offering both Strict and Warn and Continue modes, the Spectral Scanner Tool accommodates users with diverse requirements for configuration validation. Users can select the mode that best aligns with their workflow and risk tolerance.
1. Strict Mode (Default)
In this mode, the Spectral scanner strictly validates user configurations. If any misconfiguration is detected, the scan will immediately halt, and no further actions will be taken.
Use Case: This mode is ideal for users who need a high level of confidence that their configurations are correct before proceeding with the scan.
2. Warn and Continue Mode
When configured to Warn and Continue, the Spectral scanner allows the scan to proceed even if there are misconfigurations. In this case, the following issues may be handled:
- Invalid
spectra.yamlfile - Invalid custom rules
- Invalid tags
- And more
In this mode, the scanner will automatically revert any detected misconfigurations to their default values and provide users with a summary of the misconfigurations and the defaults that were applied at the conclusion of the scan.
Use Case: This mode is beneficial for users who wish to continue scanning despite minor configuration issues and are comfortable with default values being applied for any misconfigured flags.
Hardening
Enables you to control the Spectral command over different assets in your organization.
Violating the policy will either fail the Spectral command or ignore the hardened configuration, and continue with warning - according to the Fallback mode.
| Configuration | Source | Supported Version |
|---|---|---|
| OK | CLI, Local Configuration File | >= 1.10.95 |
| Exclude Tags | CLI, Local Configuration File | >= 1.10.95 |
| Exclude | CLI, Local Configuration File | >= 1.10.95 |
| Include | CLI, Local Configuration File | >= 1.10.95 |
| Ignores | Local Configuration File | >= 1.10.95 |
| Ignores Options | Local Configuration File, Inline Ignores | >= 1.10.221 |
| Fail on Error | CLI | >= 1.10.95 |
| Fail on Critical | CLI | >= 1.10.95 |
| Ignore Remote Config | CLI | >= 1.10.95 |
| Since | CLI | >= 1.10.95 |
| Max Size | CLI | >= 1.10.95 |
| Show Match | CLI | >= 1.10.95 |
| Send Local Ignores | Local Configuration File, Inline Ignores | >= 1.10.95 |
-
For scanner versions, previous to 1.10.221, that support hardening the whole
match_ignoreobject in the spectral.yaml local configuration file, hardening only part of the ignore options , will result with no hardening of thematch_ignoreconfigurations. -
Must use the latest version of the Github & GItlab bots in order to use the hardening flags.
Combining configurations
match_ignores - If a spectral.yaml file exists locally, it's match_ignores section would be merged with the asset type match_ignores section, meaning that the list of ignores would contain ignores configured locally in spectral.yaml, and also ignores defined per asset type.
For more information about ignores configuration, click here.
projects - If a spectral.yaml exists locally, the projects configuration of the asset type will not take place, and the local projects configuration would be applied if it exists in spectral.yaml.
For more information about projects configuration, click here.
Allowed RBAC roles
Owner and Admin roles are allowed to set configuration per asset type, Member role can view the configuration, but not allowed to modify it (read only mode).
For more information about roles and RBAC, please click here.
Asset type configuration usage indication
In order to figure out if an asset scan used asset type configuration, please check if scan banner named remote_cfg holds the value Yes.
Updated 10 months ago